First of all, the background of cross-validation and grid search is that tree length must be adjusted to solve excessive/depopulated suitability in the decision tree, but cross-validation and grid search have emerged because parameters cannot be changed continuously.Without a test set, it is difficult to determine whether the model is over or under-fit.An easy way to measure without using a test set is to add —-> validation sets further in the learning set.

Create Validation Set
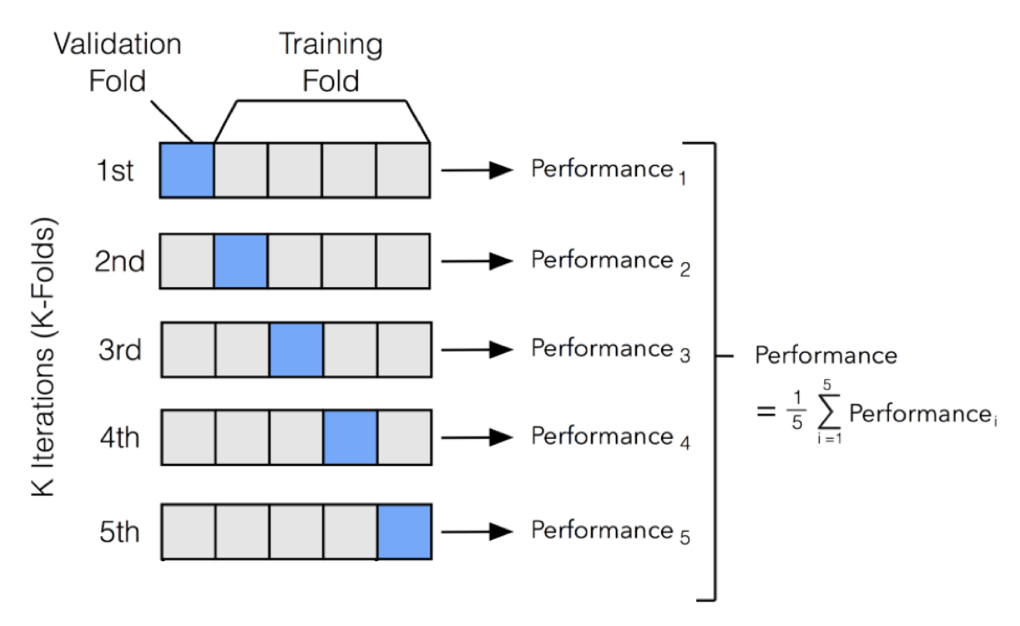
Cross validation – The more training data is used, the better the model is created. However, if too few verification sets are used, the verification score will be unstable.Cross-validation is used to address these issues.
인기글
4.png?type=w800 "How to treat Dongtan Sima Ear Treatment Oriental Medicine Clinic properly without recurrence")

")
, new standards will be applied in the future")
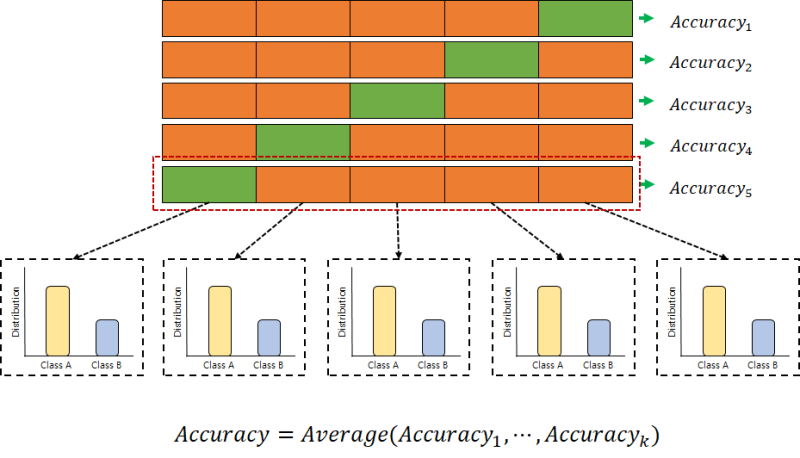
cross-validation

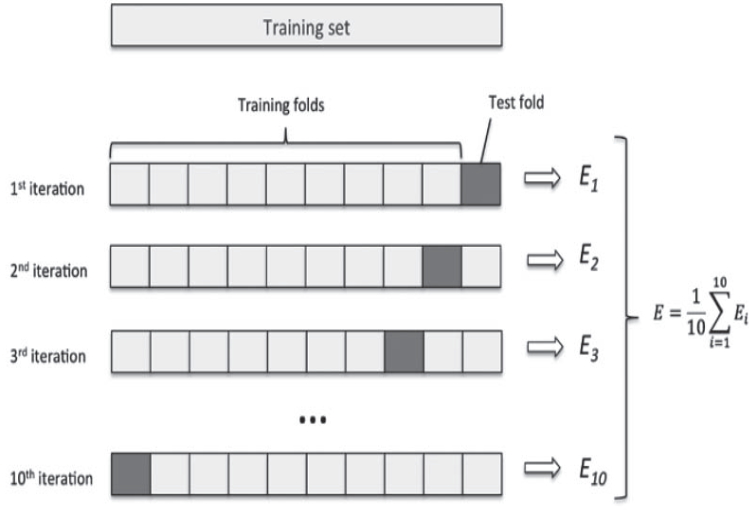
A process of separating and evaluating the verification set a plurality of times is repeated, and a final average score is obtained as an average of these scores.The above figure is called 3-Fold cross validation.* Usually, 5 to 10 folds are used frequently.There is a cross-validation function called cross_validate() in the cyclist run.
sklearn.model_proxy インポート cross_proxycores = cross_proxy(dt, train_input, train_target)

This function returns a dictionary with the fit_time, test_time, and test_score keys.The first and second keys mean training and validation time. The final average score of the intersection score can be obtained by averaging the scores contained in the test_score.
print(np.mean(scores[‘test_core’])))#This is the final average score in the scores dictionary.

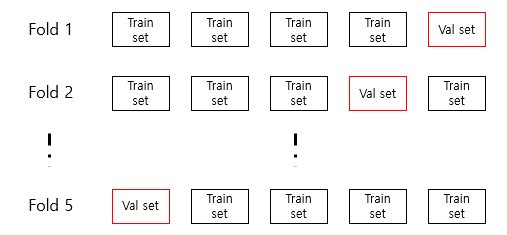
If cross-validation is performed, a splitter must be specified to mix the training sets.Cross-validation in regression uses KFold for the divider and Strated KFold for the classification model to divide target classes equally.

sklearn.model_selection Tiered from Import KFoldscores = cross_input (dt, train_input, train_target, cv = Tiered) KFold()If you want to perform a 10-fold cross-validation after mixing the training setsplitter = Tiered KFold(n_split = 10, shuffle = true, random_state = 2)// n_으로개로 10개의 하트 교로필 사진 shuffle, 보기 scores = cross_target(dt, train_input, train_target, cv= splitter)print(np.ph[‘test_score’]))In other words, it is more efficient than to see.Hyper Parameters tuning – The parameter that the machine learning model is not learned, so that the user must be specified as hyper parameters.Hyper Parameters tuning jobs ->parameters and perform cross-validation.-> ->The technology that automatically performs hyperparameters tuning without intervention.The size search (Grid Search) for the parameters to request the optimum value.The GridSearch CV class will perform a hyperparameters search and cross verification.You do not need to call the protocol.Locate the optimum value from the decision tree model to the Admin_decrelease value from the decision tree model using basic parameters1. First, import GridSearchCV classes and create a dictionary of parameters to search for and a list of values to search for from sklearn.model_selection GridSearchCVparams = {‘min_impurity_decrease’ : [0.0001,000 0.0002,000 0.0003,0004,000.0005]}1. First, import GridSearchCV classes and create a dictionary of parameters to search for and a list of values to search for from sklearn.model_selection GridSearchCVparams = {‘min_impurity_decrease’ : [0.0001,000 0.0002,000 0.0003,0004,000.0005]}gs = GridSearch CV(DecisionTreeClassifier(random_state = 42), params, n_jobs = -1)//Transmit as soon as you create an object in the decision tree class //Then tell gs.fit() to train the general modelgs = GridSearch CV(DecisionTreeClassifier(random_state = 42), params, n_jobs = -1)//Transmit as soon as you create an object in the decision tree class //Then tell gs.fit() to train the general modeldt = gs.best_module_print(dt.score(train_input, train_target))print(gs.best_params_)print(gs.cv _module_[‘skeen_test_score’])dt = gs.best_module_print(dt.score(train_input, train_target))print(gs.best_params_)print(gs.cv _module_[‘skeen_test_score’])best_index = np。argmax(gs).Print cv_results[‘mean_test_score’]).cv_results_[‘params’][best_index])After organizing this process, 1. Specify the parameters to search for.2.Run a grid search in the training set to find the combination of parameters that give you the highest average score.3. grid Search retrains the final model with a complete training set with the best parameters.4. This model is also a grid Applies to search models.And finally, let’s do a little bit more complicatedparams = {‘min_classifier’}: np.arange(0.0001, 0.001, 0.0001), ‘max_depth’: range(5, 20, 1), ‘min_classifier_vlan’ : range(2, 100, 10) }gs = GridSearchCV(DecisionClassifier (random_state = 42)、 params= -1、n_vlanages= -1)prantage(gs.bootmlinterflYou can find the best parameters by listing them without cross-validation while changing them one by one.However, there is a regret here.Random Search – The range of parameter values is too large, but if there are too many parameters, it takes a long time to run. – In such cases, random I’ll do a search.Random search does not pass a list of parameter values, but rather a probability distribution object that can be sampledfrom scipy.stats import uniform. The uniform and random in the randint # sub-package are all subtracted equally within a given range.# “Sampling this from an even distribution” #randint subtracts an integer value, and uniform subtracts a real value.from scipy.stats import uniform. The uniform and random in the randint # sub-package are all subtracted equally within a given range.# “Sampling this from an even distribution” #randint subtracts an integer value, and uniform subtracts a real value.rgen = randint(0, 10)rgen.rvs(10). # A value between 0 and 10 is randomly outputted 10 times #np.unique(rgen.rvs(1000), return_counts=True)# is outputted.Think of it as similar to a random number generator.params = {‘min_depth_leaf’: uniform(0.0001, 0.001), ‘max_depth’: randint(20, 50), ‘min_depth_report’: randint(2, 25), ‘min_depteles_leaf’: randint(1, 25)Loading a Random Search LibraryFrom sklearn.model_selection import Randomized Searched CVgs = Randomized Searched CV(Decision Classifier (random_state = 42), params, n_iter = 100, n_jobs =-1, random_state = 42)#n_iter is sampled 100 times in the parameter range to find the best combination of parameters.Grid search and random search are used to optimize depopulation and overfitting.This is what I summarized after reading this book.Machine Learning to Study Alone + Deep Learning Author Park Hye-sun Publishing Hanbit Media Launch 2020.12.21。git hub +STAR는 사랑입니다https://github.com/kalelpark/Alone_ML_DLGitHub – kalelpark/Alone_ML_DL: Click . Create an account on GitHub.github.com to help develop kalelpark/Alone_ML_DLGitHub – kalelpark/Alone_ML_DL: Click . Create an account on GitHub.github.com to help develop kalelpark/Alone_ML_DLGitHub – kalelpark/Alone_ML_DL: Click . Create an account on GitHub.github.com to help develop kalelpark/Alone_ML_DL